How to Build Text Based Image Search
Using multi-modal text and image embedding models for text based and image based image search with python and transformers.
Searching for images is an image classification task. There are 2 types of image classification:
-
Normal Image classification.
Classify an image into a preset list of categories. -
Zero-shot Image classification.
Classify an image into classes previously unseen during training of a model.
Normal Image classification
These models are trained with a list of categories and predicts which of these categories the image falls into.

from transformers import pipeline
# Create the pipeline with the `google/vit-base-patch16-224` model
clf = pipeline("image-classification", "google/vit-base-patch16-224")
# Get the categories
results = clf("temp/lake-smaller.jpg")
print(results)
{'label': 'lakeside, lakeshore', 'score': 0.9137738943099976}
{'label': 'seashore, coast, seacoast, sea-coast', 'score': 0.017617039382457733}
{'label': 'promontory, headland, head, foreland', 'score': 0.016670119017362595}
{'label': 'valley, vale', 'score': 0.007515666540712118}
{'label': 'dam, dike, dyke', 'score': 0.004389212466776371}
You can then save these categories (at least the ones scoring above 0.1) in a database and then use these to search and for images matching the search term.
However, the above approach will match "lake" but not "water", or "river".
The google/vit-base-patch16-224 is a small 86.6M params (346 MB) size model which predicts one of the 1000 ImageNet classes.
There is also the larger google/vit-large-patch16-224 model (1.22 GB) which is more accurate, but larger and slower.
The name means:
vit: Vision Transformer (ViT).
base: the size of the model.
patch16: Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
224: All images are resized to a resolution of 224x224 pixels before being fed to the model.
Zero-shot Image classification
In order to get arbitrary matching and score the similarity between the search term and the image, regardless of what the search term is you need a zero-shot image classification model.
These are embedding models which have a shared embedding space where the embeddings of text representations of an image, and the image data itself are trained to end up with similar coordinates in the embedding space.
This means when you calculate the distance between the search terms embedding, and the embeddings of several images you get how similar each one is to the search term.
This also means "ice" will be similar to photos of "snow" even though the words are different.
2 good models for this are:
- OpenAI CLIP model.
- Google SigLIP 2
CLIP large is a 0.4B (1.71GB) model. The smaller openai/clip-vit-base-patch32 is only 605MB and is the more popular version. Both as fairly small, quick models.
However, the models were released 2021, and since then newer models have been trained which surpass them in benchmarks.
SigLIP 2 is a family of models released by Google in February 2025, which claims to outperform their previous counterparts at all model scales in core capabilities.
The models come in various sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
There are also fixed size versions which resize and crop images to a fixed square resolution, or flexible resolution and aspect ratio versions, which divide the image into the fixed size tiles, but divide up images of different sizes and resolutions.
FG-CLIP 2 is a new model released in October which claims to further improve image classification results.
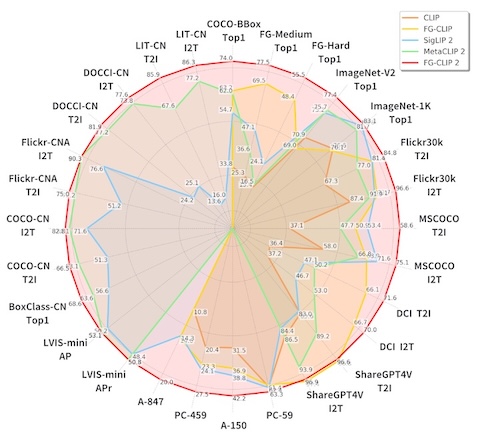
It comes in base (1.54GB), large (3.59GB), and so400m (4.62GB) versions.
Simple Zero-shot Classification Example
If you just want to classify an image into several categories which you provide the huggingface transformers pipeline.
from transformers import pipeline
classifier = pipeline("zero-shot-image-classification", model="openai/clip-vit-large-patch14-336")
candidate_labels = [
"2 cats",
"a plane",
"a remote",
"a bear",
"a ocean",
"a water",
"a river",
"a lake",
"a pond",
"rain",
"a mountain",
"a car",
]
image = load_image("temp/lake-smaller.jpg")
results = image_classifier(image, candidate_labels)
print(results)
{'score': 0.9330312609672546, 'label': 'a lake'}
{'score': 0.02649594098329544, 'label': 'a water'}
{'score': 0.023041551932692528, 'label': 'a river'}
{'score': 0.01358820404857397, 'label': 'a pond'}
{'score': 0.0017832380253821611, 'label': 'a ocean'}
{'score': 0.0006893535610288382, 'label': 'a mountain'}
{'score': 0.0004389677778817713, 'label': 'a phone'}
{'score': 0.00038122545811347663, 'label': 'a remote'}
{'score': 0.0002814349136315286, 'label': 'a plane'}
{'score': 0.00019272200006525964, 'label': 'rain'}
{'score': 3.4059521567542106e-05, 'label': 'a car'}
{'score': 3.0467408578260802e-05, 'label': 'a bear'}
{'score': 1.143596091424115e-05, 'label': '2 cats'}
Using the google/siglip2-so400m-patch16-naflex model we get roughly the same results, though the scores are all much lower (the order is still good though).
from transformers import pipeline
image_classifier = pipeline(model="google/siglip2-so400m-patch16-naflex", task="zero-shot-image-classification")
outputs = image_classifier(image, candidate_labels)
print(outputs)
{'score': 0.1465340554714203, 'label': 'a lake'}
{'score': 0.0038345942739397287, 'label': 'a water'}
{'score': 0.001178617007099092, 'label': 'a river'}
{'score': 0.00041009532287716866, 'label': 'a ocean'}
{'score': 0.00018598142196424305, 'label': 'a mountain'}
{'score': 8.42182053020224e-05, 'label': 'a pond'}
{'score': 3.1798244890524074e-05, 'label': 'rain'}
{'score': 1.0240605661238078e-05, 'label': 'a plane'}
{'score': 1.7888405636767857e-06, 'label': '2 cats'}
{'score': 1.6506612610101001e-06, 'label': 'a bear'}
{'score': 5.040944870415842e-07, 'label': 'a phone'}
{'score': 4.662872470362345e-07, 'label': 'a car'}
{'score': 3.0268274997524713e-08, 'label': 'a remote'}
Text to Image Search
However, if we want to build up a database of image embeddings and do image text and image based searches against those embeddings we need to get the embeddings from these models.
Example Images



Generate Image Embeddings
import torch
from PIL import Image
from transformers import CLIPProcessor, CLIPModel
import numpy as np
import torch.nn.functional as F
def generate_image_embedding(image_path):
"""
Generate an L2-normalized image embedding.
Args:
image_path: Path to the image file
Returns:
Tuple of (filename, embedding vector as numpy array)
"""
device = get_device()
model, processor = get_clip_model()
# Load and convert image to RGB
image = Image.open(image_path).convert("RGB")
# Generate embedding
with torch.no_grad():
inputs = processor(images=image, return_tensors="pt").to(device)
features = model.get_image_features(**inputs)
# L2 normalize for proper cosine similarity
features = F.normalize(features, p=2, dim=-1)
embedding = features.cpu().numpy()[0]
# Extract just the filename from the path
filename = image_path.split("/")[-1]
return filename, embedding
Generate Text Images.
def generate_text_embedding(query_text):
"""
Generate an L2-normalized text embedding.
Args:
query_text: Text query string
Returns:
Embedding vector as numpy array
"""
device = get_device()
model, processor = get_clip_model()
with torch.no_grad():
inputs = processor(text=[query_text], return_tensors="pt", padding=True).to(device)
features = model.get_text_features(**inputs)
# L2 normalize
features = F.normalize(features, p=2, dim=-1)
embedding = features.cpu().numpy()[0]
return embedding
Load the image embedding
def load_images():
"""
Load all images and generate their embeddings.
Returns:
List of tuples: [(filename, embedding), ...]
"""
print("Loading and embedding images...")
embeddings = []
for image_path in IMAGE_PATHS:
print(f" Processing {image_path.split('/')[-1]}...")
filename, embedding = generate_image_embedding(image_path)
embeddings.append((filename, embedding))
print(f"Generated embeddings for {len(embeddings)} images\n")
return embeddings
Compare image embedding.
def search(query_text, image_embeddings):
"""
Search for images matching the text query.
Args:
query_text: Text description to search for
image_embeddings: List of (filename, embedding) tuples
Returns:
List of (filename, similarity_score) tuples sorted by similarity (best first)
"""
print(f"Searching for: '{query_text}'")
# Generate text embedding
text_embedding = generate_text_embedding(query_text)
# Compare with all image embeddings
results = []
for filename, image_embedding in image_embeddings:
similarity = cosine_similarity(text_embedding, image_embedding)
results.append((filename, similarity))
# Sort by similarity (highest first)
results.sort(key=lambda x: x[1], reverse=True)
print("\nResults:")
print("-" * 50)
for filename, similarity in results:
print(f"{filename:30s} | Similarity: {similarity:.4f}")
print("-" * 50)
print()
return results
Example compare the images.
image_embeddings = load_images()
search("a beautiful lake with mountains", image_embeddings)
Results
Searching for: 'a beautiful lake with mountains'
Results:
----------------------------------------------------
lake-smaller.jpg | Similarity: 0.2865
beech-tree.jpg | Similarity: 0.1330
cats.jpg | Similarity: 0.1164
bmw-i7.jpg | Similarity: 0.1073
----------------------------------------------------
Searching for: 'luxury car'
Results:
----------------------------------------------------
bmw-i7.jpg | Similarity: 0.2513
beech-tree.jpg | Similarity: 0.1920
cats.jpg | Similarity: 0.1818
lake-smaller.jpg | Similarity: 0.1685
----------------------------------------------------
Searching for: 'tree in nature'
Results:
----------------------------------------------------
beech-tree.jpg | Similarity: 0.2992
lake-smaller.jpg | Similarity: 0.2080
cats.jpg | Similarity: 0.1543
bmw-i7.jpg | Similarity: 0.1377
----------------------------------------------------
Searching for: 'water and nature'
Results:
----------------------------------------------------
lake-smaller.jpg | Similarity: 0.2672
beech-tree.jpg | Similarity: 0.2209
cats.jpg | Similarity: 0.1669
bmw-i7.jpg | Similarity: 0.1512
----------------------------------------------------
Search By Image
You can also do an image search by generating an image embedding and using that for the comparisons instead of using the text embedding.
def search(image_path, image_embeddings):
print(f"Searching for: '{image_path}'")
# Generate text embedding
_, search_image_embed = generate_image_embedding(image_path)
# Compare with all image embeddings
results = []
for filename, image_embedding in image_embeddings:
similarity = cosine_similarity(search_image_embed, image_embedding)
results.append((filename, similarity))
# Sort by similarity (highest first)
results.sort(key=lambda x: x[1], reverse=True)
print("Results:")
print("-" * 50)
for filename, similarity in results:
print(f"{filename:30s} | Similarity: {similarity:.4f}")
print("-" * 50)
print()
return results
As the image embeddings and text embeddings are designed to end up in a similar location in the multi-dimensional embedding space either can be used for lookups and get good results.
References
Image Classification References
- huggingface docs: Image Classification
- huggingface: google/vit-base-patch16-224
- huggingface: google/vit-large-patch16-224
Zero-Shot Image Classification References
CLIP References
- OpenAI: CLIP: Connecting text and images
- Github: openai/CLIP
- huggingface docs: clip
- huggingface: openai/clip-vit-base-patch32
- huggingface: openai/clip-vit-large-patch14
SigLIP 2 References
- huggingface papers: SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
- arxiv: SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
- huggingface: google/siglip2-base-patch16-naflex
- huggingface: google/siglip2-so400m-patch14-224
- Github: google/big_vision siglip2.md
FG-CLIP 2 References
- FG-CLIP 2 Project Page
- huggingface papers: FG-CLIP 2: A Bilingual Fine-grained Vision-Language Alignment Model
- arxiv: FG-CLIP 2: A Bilingual Fine-grained Vision-Language Alignment Model
- huggingface fg-clip-2 collection
- huggingface qihoo360/fg-clip2-base
- huggingface: qihoo360/fg-clip2-large
- huggingface: qihoo360/fg-clip2-so400m
- GitHub: 360CVGroup/FG-CLIP