My New Website
The design and architecture of my new website
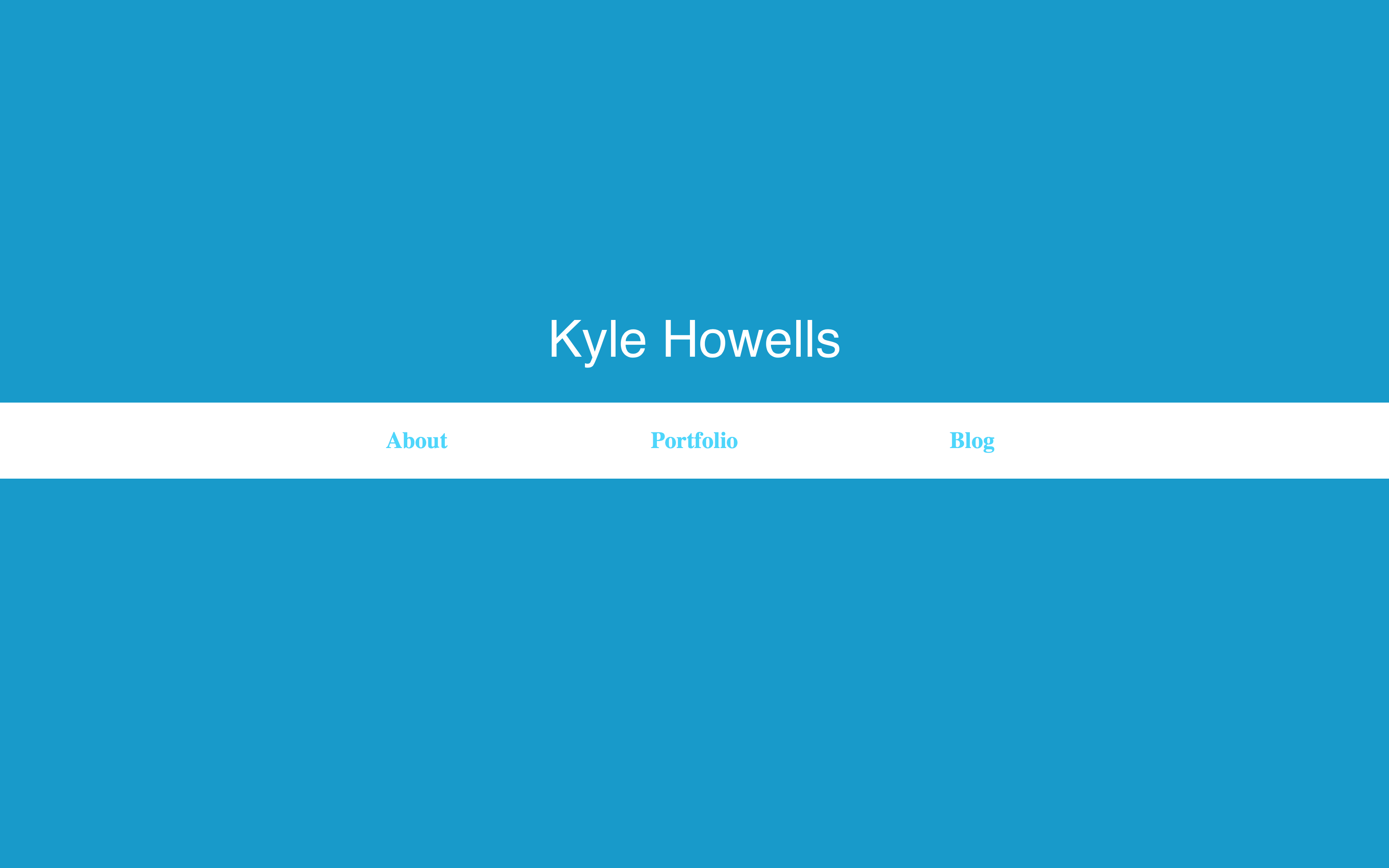
Since I started learning programming I've had a few different websites. I've used Weebly, Wordpress and Tumblr. But I'd always wanted to (and had never gotten around to) make my own website.
Now, finally, I have.
TLDR: The website is written in Python using Flask, running on an Ubuntu VPS from DigitalOcean and the blog posts are written in CommonMark (for now).
The front end is hand written HTML and CSS with minimal Javascript (2 main functions).
Visual Design
Before I started on writing any server side code, I created a few example pages to establish the visual style I wanted.
I am not a designer. I am a programmer who likes good UI and wishes he was good at design.
So to compensate, I look around for examples of design I like and save them. I started doing this with designs I particularly like on dribble and other sites.
At the time of writing this, my "UI" folder on my NAS contains 17 sub folders and 1089 images (yes, I should probably just use pinterest. I don't because I want them locally so I can run image/color analysis algorithms on them, if I ever get around to writing any that is...).
UI Prototypes
I'm never sure how to start things. Whether it is a piece of writing, UI design or a website. I struggle to think of how to introduce things. One option I could have used was to simply have my website start on the blog index. However, I wanted multiple different sections to the website. Just as importantly I wanted them to feel like different sections, not simply set apart pages of the blog. The home page was inspired by @chpwn and a few other developers (though the rest have all changed their websites' designs).

For the rest of the site I used the top navigation bar (found on almost every website) and played around until I was happy with the design. Though I ended up tweaking things here and there anyway when I came to implement it properly.
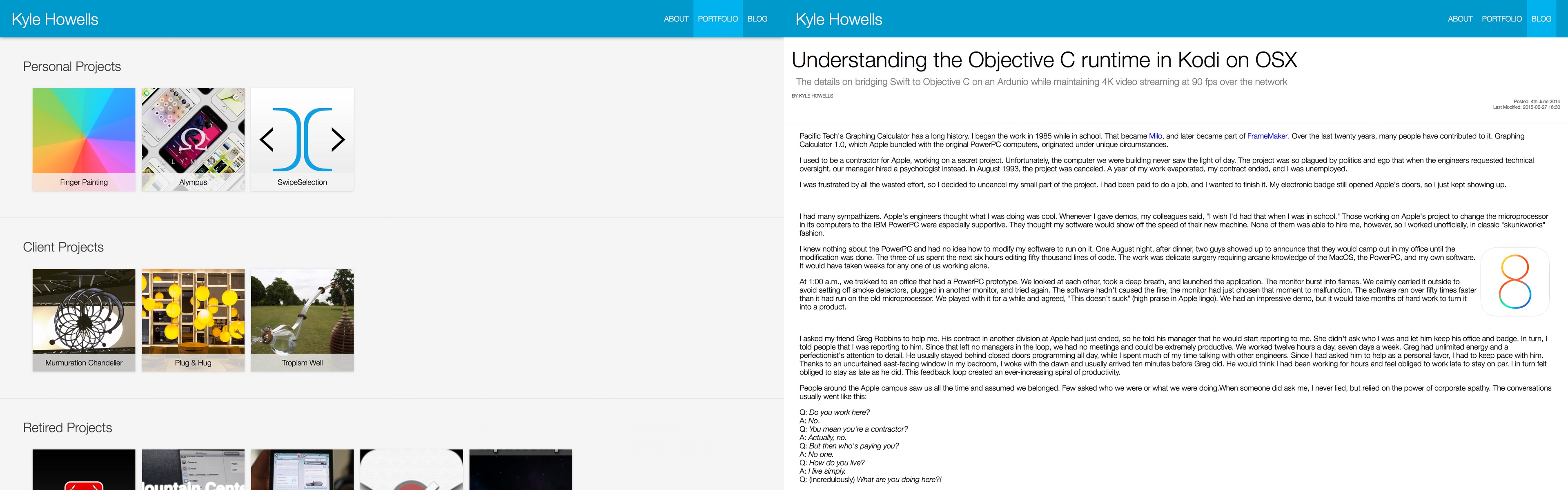
If you are wondering about the example blog post, the title is obviously nonsense but, rather than use Lorem Ipsum for the body text, I used this incredible story about the Graphing Calculator Apple bundled with the original PowerPC computers.
The Final Designs
I added a drop shadow to the navigation bar, vertically centred the home page and went back on my decision to let the content pages (such as the portfolio project pages and blog posts) go full width no matter the screen width. Overall though I kept things mostly the same.
For the projects themselves I didn't actually decide on the design until I started writing the actual site. I originally planned for each of the projects to get a custom design specific to that project. That plan ended when I realised I don't have enough imagination to pull off more than 10 custom designs, each for incredibly similar projects.
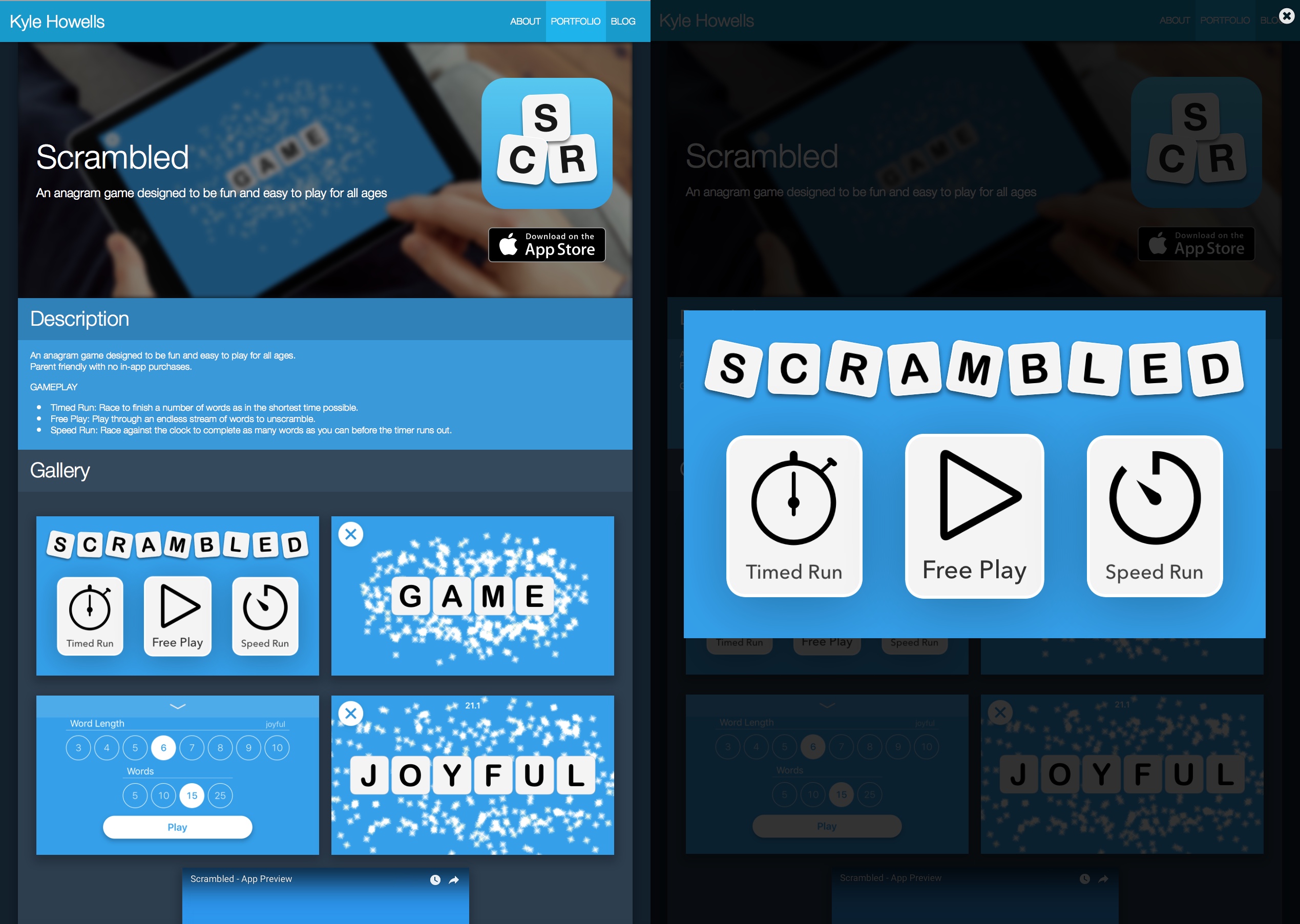
In the end I created a template I can customise to different projects and alter slightly for different types of projects. The app pages get the app icon and a link to the AppStore. The other types of projects simply get links to whatever official website the project has.
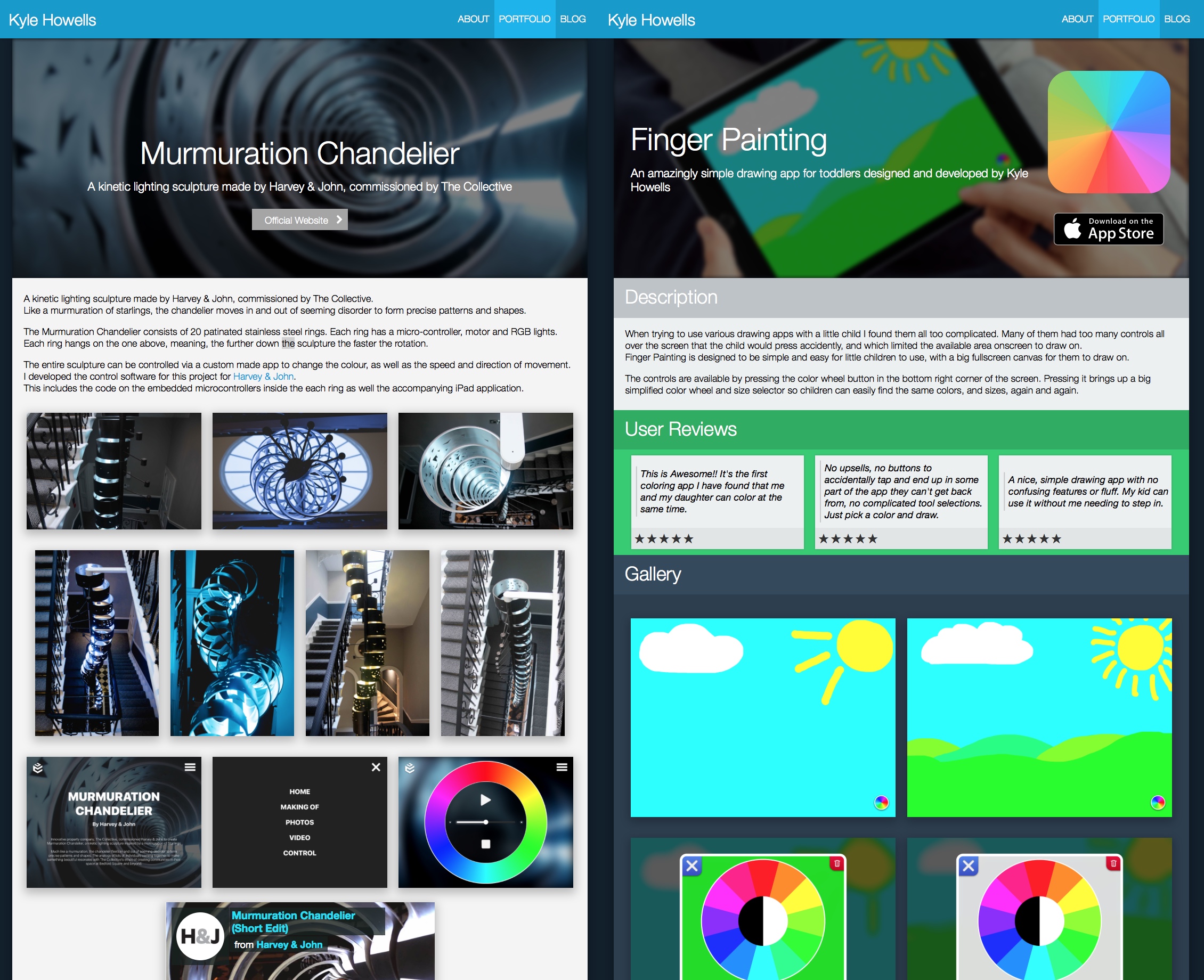
I spent a lot of time finding personal websites I liked the designs of and then looking at, and comparing, the “about me” pages. In the end what I ended up writing turned into a mini-portfolio page on its own. I’m not completely happy with the design but I’ll keep working on it over time.
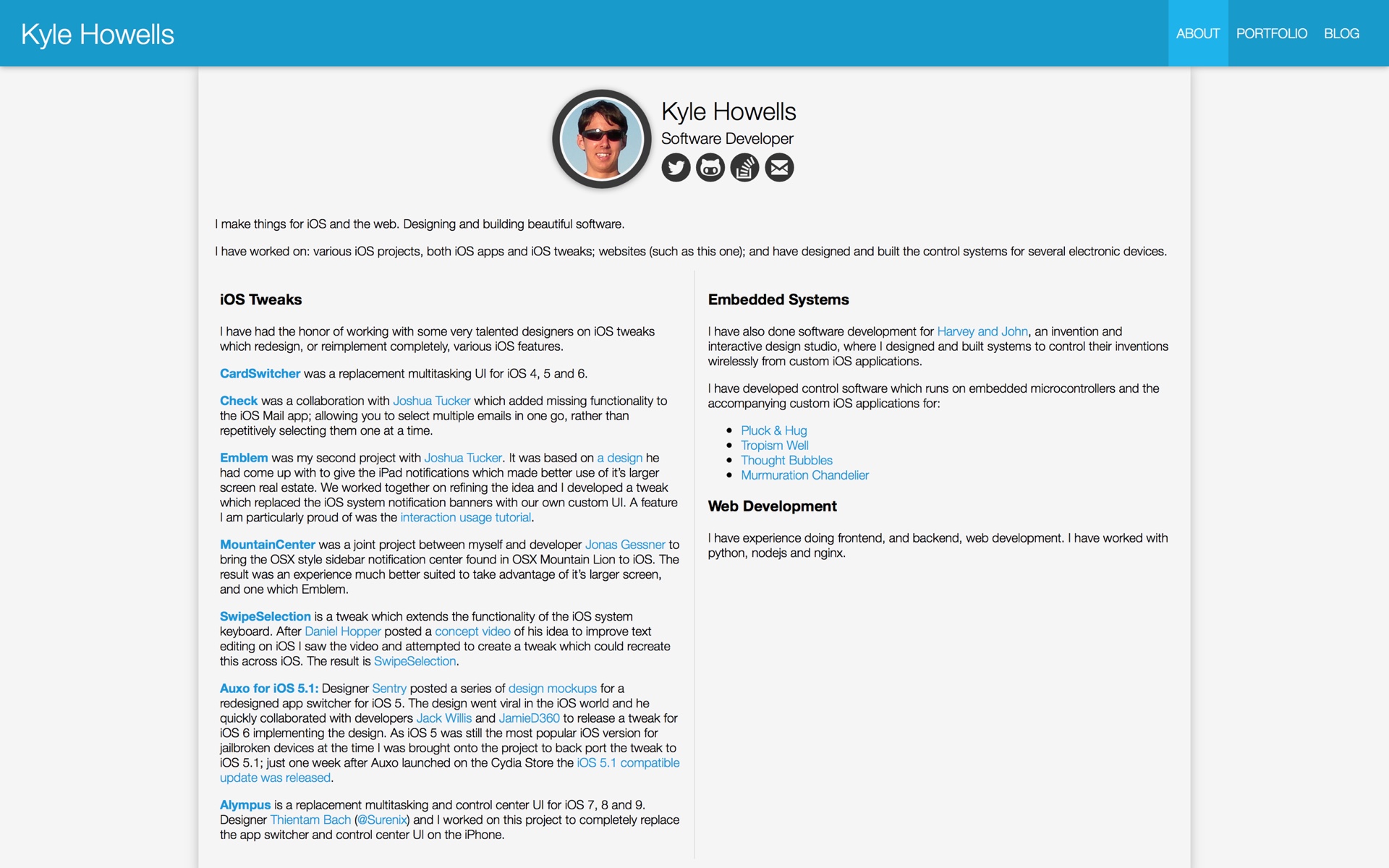
I had originally planned to have the blog posts go full width across the browser window. However, I made this decision while using a 13" MacBook Pro as my main computer. In the interim, between deciding that and implementing it, I switched to using a desktop computer with extra wide screen monitor and reconsidered my earlier position.
For overall style I tried to emulate the look of Github’s README files.
A feature I particularly like on Medium, that lots of writing applications have (but very few websites), is the estimated reading time they display right at the top of the page. As soon as I load the article I know roughly how long I need, and if I should set it aside to read later.
If it is within the last week, the published, and modified (I believe both should be shown on blog posts) labels display how long ago that event was, instead of the actual date. However, the actual date and time is always included in the ‘title’ attribute. Hovering over the relative timestamps should prompt the browser to display the real time stamp.
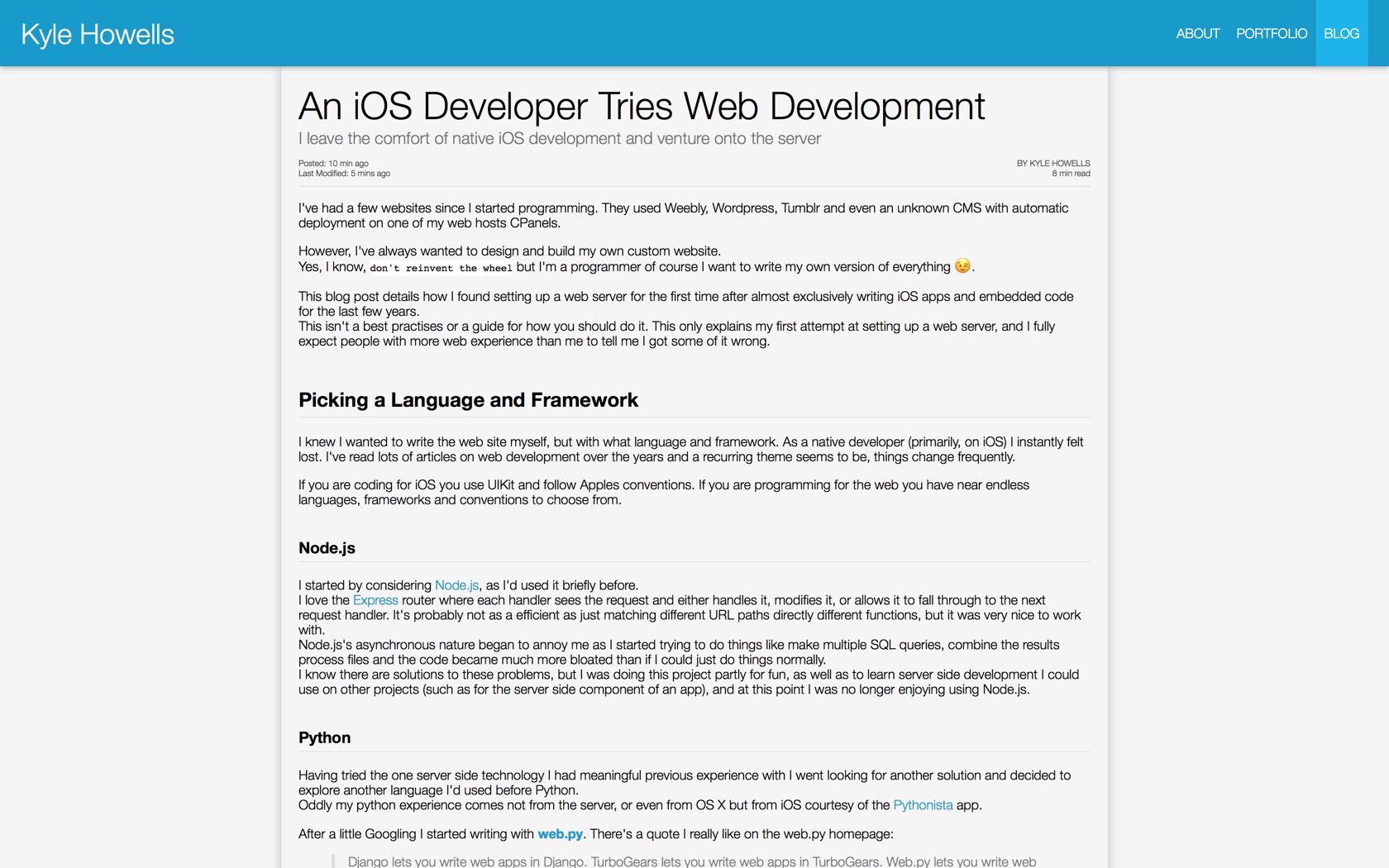
For categorising posts I decided to use tags instead of categories. In my mind categories are like folders. A post can be put inside a single category. Whereas, multiple tags can be attached to a single article. So if I write about releasing a new iOS fitness app I can tag it with: iOS, fitness, press release, etc...
Later I can lookup all the iOS related blog posts I’ve written, or every press release, etc...
Code Design and Implementation
Project Structure
The public facing web server itself is Nginx, running on an Ubuntu VPS from DigitalOcean. Nginx is set up to try to serve files in the following order:
- The static resources directory.
- The static pages directory.
- The cache directory.
- Finally it will forward the request to the python web app.
This setup minimises the requests that make it to the python application and allows me to easily cache blog posts, and any other pages I want to be dynamic some of the time.
server {
listen 80;
server_name ikyle.me www.ikyle.me;
charset utf-8;
root /var/www/ikyle;
index index.html index.htm;
location / {
try_files /static_files$uri /static_files$uri/index.html
/static_pages$uri /static_pages$uri/index.html
/cache$uri /cache$uri/index.html @blog;
}
location @blog {
include uwsgi_params;
uwsgi_pass unix:/var/www/ikyle/ikyle_uwsgi.sock;
}
}
One optimisation I have been thinking about doing is to: move the cache in front of the static files directory; extend the python application to monitor for changes to css and javascript files inside the static directory; and have it automatically run a minifier on those files, placing the output in the cache directory.
I don’t know what the conventions are for structuring Python applications, but this is the file structure I went with.
Root
+-- error_pages/
| Static error pages (404, etc...) are stored in here
+-- static_files/
| Static files (css, js, images, etc...) go in here (can be cached)
+-- static_pages/
| Static pages from the website (such as the about me and portfolio pages) go in here. (not to be cached)
|
+-- cache/
| Rendered blog posts, etc go in here.
|
|
+-- portfolio/
| +-- input/
| | +-- categories.json
| | | Defines the different categories of portfolio projects, and their order
| | *-- 'folder_name'/
| | Projects each have their own folder
| | +-- media/
| | | This folder contains all the images and videos for the project
| | +-- info.json
| | | This file defines everything about the project
| | *-- 'file'.md
| | Any markdown files will be rendering into HTML files and placed as directories to the project itself
| |
| +-- templates/
| | The templates for the porfolio pages go in here
| |
| `-- renderer.py
| Processes the input files and generates the resulting HTML pages
|
|
+-- blog.db
| The SQLite file that acts as the websites database.
+-- app.py
| Application entry point
+-- api/
| +-- api.py
| | The python api through which the websites posts are accessed and searched
| `-- utility.py
| Functions shared across different pages, such as rendering Markdown and caching pages.
`-- web/
+-- templates/
| The html templates that generate the web pages.
| +-- blog/
| The folder the blog templates are stored
| `-- admin/
| The folder the admin templates are stored
|
+-- webapi.py
| The public facing json web api endpoint.
`-- blog.py
The public html blog
The top few directories are simply to place HTML, CSS and other static files in. The next part is the portfolio directory. This acts as its own subproject, separate from the rest of the application.
As most of my projects are very similar (predominantly being iOS apps) I decided that I would create a template, like I had set up for the blog posts.
To create a new project page I create a new directory for it. Inside that directory I create an info.json file and fill out the relevant information, such as: category; title; description; description; any press or reviews it has received; relevant images and videos; and links to related web pages.
The rendered.py script takes the information from the info.json files, passes it into the template and saves the result, along with the media, into the static_pages directory.
At the moment, I just run this locally on my computer and sync the resulting files onto the server. Adding a new project to my portfolio isn’t something I do regularly enough for me to have created a web UI for this yet.
Finally, the last chunk is the actual Flask application itself.
The Flask Application
The application is separated into 3 sections: the api; the blog; and the webapi.
The api directory contains a utilities file, with functions I use throughout the application, and the api.py file that handles all database access for blog posts.
As you might have noticed in the file directory structure, I use SQLite for the database. Before you start, yes I know.
Think of SQLite not as a replacement for Oracle but as a replacement for fopen()
However, the reasons I choose to use SQLite are as follows.
- My dataset is small.
The dataset is my blog posts. Even after years of active blogging, we are only talking a few thousand text documents. - My expected load is minimal.
As much as I’d like to imagine otherwise, my posts are unlikely to generate very much traffic. - I’m lazy.
Choosing SQLite gave me: a quick and easy setup on the web server; the ability to run the website locally on OS X with minimal fuss; trivial backups; and easy full text search.
Having said that, I am reconsidering the way I handle storing blog posts, which I’ll detail more in the possible changes section at the end of this post.
The api.py file handles opening, closing and querying the database. Posts are returned as a custom Dict subclass that allows you to access keys like attributes.
# Convience Dict Subclass
# Allows dict["name"] to be queried via dict.name
class DBItem(dict):
def __getattr__(self, name):
if name in self:
return self[name]
else:
return None
def __setattr__(self, name, value):
self[name] = value
def __delattr__(self, name):
if name in self:
del self[name]
The biggest part of the file is the get_posts() function. Rather than using several different functions to query different things, this takes several parameters, validates they are within allowed ranges, and builds the correct query string. Then it processes the result into an array of post objects.
# Search posts
def get_posts(query=None, sortDescending=True, before=None, after=None, summary=True, limit=25, tags=None):
...
# How many results does the search potentially return
def get_posts_count(query=None, before=None, after=None, tags=None):
...
This function is delicate enough that, if this was for something other than my personal blog, I would separate it into 3 distinct parts (the validation; query string building and result building) which could have tests run against them. However, setting up and writing tests for this, (and the different URL endpoints) isn’t worth it to me. If there is a bug I know exactly which file handles that part of the website and can deploy a fix within minutes.
The 2 web facing parts of the website are split between webapi.py and blog.py, which are each separate Flask Blueprints.
app.py sets up Flask and adds my custom functions to the jinja2 template engine and registers the webapi and blog blueprints to the relevant url_prefix.
webapi.py is basically a thin JSON wrapper around the blog api.
For example: ikyle.me/blog/api/post?id=1 will return the first blog post’s Dict (which should be this post) dumped as a JSON file (including the content as markdown, rather than HTML).
This is the relevant code (just with some sanity checks removed).
post = api.get_post( request.args.get('id') )
r = flask.make_response( json.dumps(post) );
r.mimetype = 'application/json';
return r
I created the JSON api so that I have easy API access to my blog, in case I want to make an iOS app or something similar. However, the only endpoints that require authentication are the ones to create, modify or delete a blog post. The two needed for browsing are open.
/blog/api/post?id=
/blog/api/search
blog.py is similar to webapi.py but with the extras required for managing a website rather than an API endpoint. It queries the api, renders the posts, handles (most) server errors and generates the blog's Atom feed (yes it has one, I just haven’t added an icon linking to it yet).
The Atom feed is generated by the AtomFeed class from the Werkzeug contrib package.
I also use Flask-Login to manage access to a set of very basic admin features I built into the website. These consist of a basic blog post editor and buttons that appear allowing me to create, edit or delete posts.
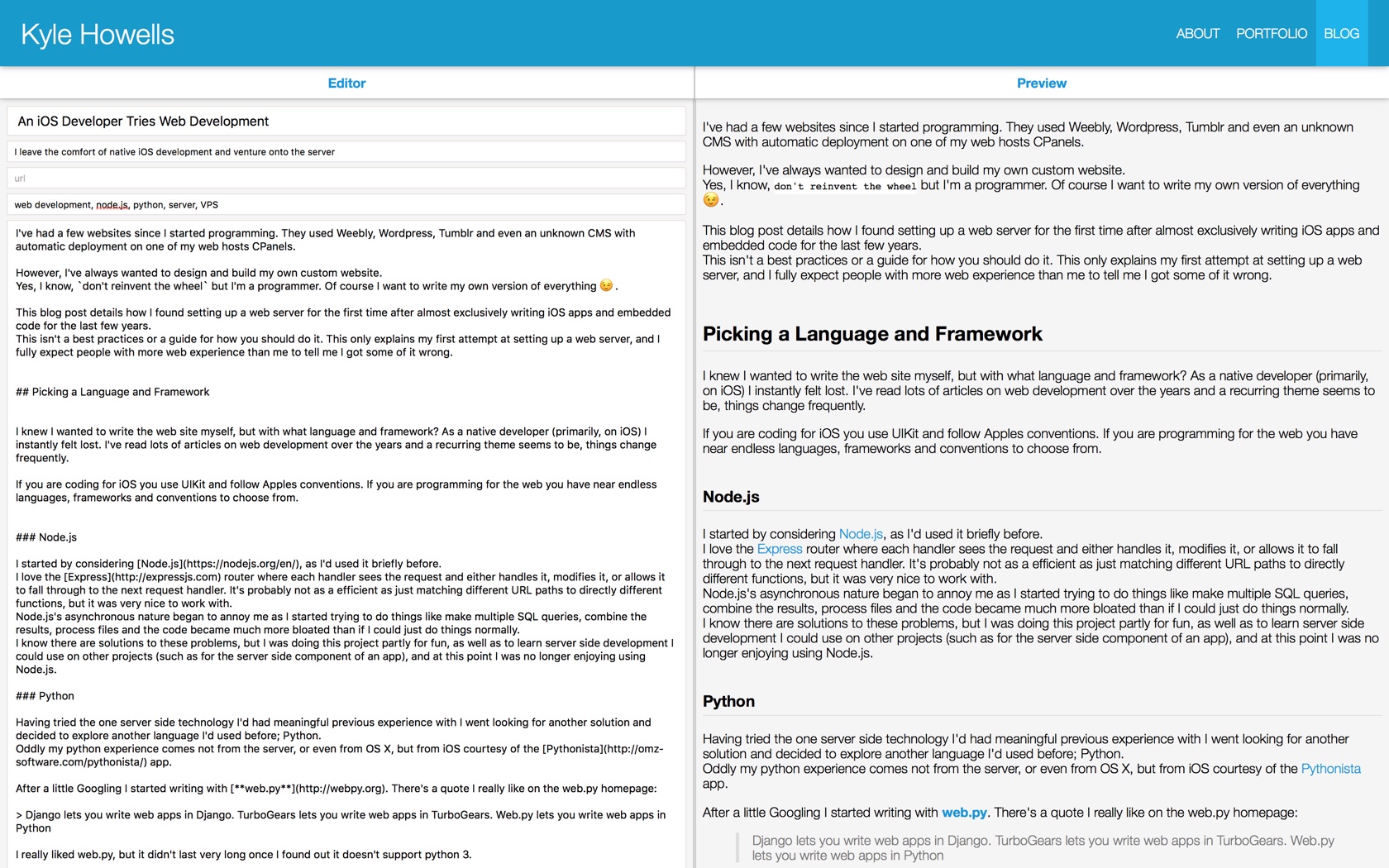
As I (for the moment) use unmodified CommonMark, I am able to use the JavaScript reference implementation to locally generate a live preview of the post as I am writing it. This is almost identical to the commonmark.js dingus. One of the extra things I need to do is refresh the syntax highlighting.
var commonmark = window.commonmark;
var writer = new commonmark.HtmlRenderer();
var htmlwriter = new commonmark.HtmlRenderer();
var xmlwriter = new commonmark.XmlRenderer();
var reader = new commonmark.Parser();
function debounce(func, wait, immediate){ /* https://davidwalsh.name/javascript-debounce-function */}
document.addEventListener("DOMContentLoaded", function(event) {
hljs.configure({languages: []}); // Don't auto detect languages
var article_text = document.getElementById("article_textarea");
var preview_holder = document.getElementById("article_preview_div");
var render_markdown = debounce(function() {
var parsed = reader.parse(article_text.value);
var renderedHTML = writer.render(parsed);
preview_holder.innerHTML = renderedHTML;
highlight_code(preview_holder);
}, 250);
article_text.onchange = function() { render_markdown(); };
article_text.oninput = function() { render_markdown(); };
// Call them once at the start
render_markdown();
}
function highlight_code(element) {
var elements = element.getElementsByTagName('pre');
for (var i = 0; i < elements.length; i++) {
var pre_block = elements[i];
var possible_block = pre_block.children[0];
if (possible_block.tagName == "CODE") {
hljs.highlightBlock(possible_block);
}
}
}
Future Changes
I’m happy I have the site at a point I can push it live. However, this is not how the website will always be. Even now, there are lots of things I want to change.
At the moment, the website isn’t optimised very much. I designed a cache directory into the design from the beginning, but don’t use it at present.
Both the blog posts and atom feed are dynamically generated on every request. An obvious gain would be to cache both of these.
The atom feed could be saved and only regenerated every time a blog post is changed, rather than on every request.
Blog posts have friendly dynamic timestamps, but only for the first week (which is also the time a post is most likely to be edited). Thereafter, they could be cached indefinitely, only needing to be regenerated if modified. Alternatively, the friendly timestamps could be generated locally with javascript, allowing the posts to be cached from the start.
I am currently writing this post using iA Writer on my MacBook, rather than in the post editor I spent the time to make, because I didn’t think to add the ability to save (or even the concept of) drafts.
Using CommonMark has its advantages. I can use any CommonMark compatible renderer unmodified and my blog posts will render correctly.
Despite this, I don’t think my blog will use standard CommonMark for very long.
One missing feature I was shocked to find out isn’t part of either Markdown or CommonMark is footnotes. I was particularly surprised given that John Gruber is the original author of Markdown and his website, daringfireball.net, uses footnotes in almost every post.
This should be a footnote.[^comment]
[^comment]: Sadly this syntax isn't supported for some reason.
I would have used this feature extensively while writing this article. Almost everywhere I have included a comment in (brackets), and some of the comments blocked by commas, would have instead been a footnote. I left out a lot of small related comments I have about different sections of this post because I would have put them in a footnote, and adding them into the main body of the text would divert that section off course too far from its original topic.
If I’m going to give up compatibility with the CommonMark spec I might as well go all the way. Other non-standard extensions I’d like include:
- Tables
- Checkboxes
- The image syntax extended to include videos automatically, based on the file extension.
John Gruber has stated that for things Markdown doesn’t include you should use HTML directly. However, one of my reasons for using Markdown is to avoid using HTML directly.
Keep in mind that making a native iOS app is always faintly at the back of my mind, even if I end up never getting around to it. Including HTML in your markdown might be fine if the markdown is just going to be rendered out to HTML. But, if the result is going to be rendered differently (by iOS’s text rendering engine for example) HMTL is just going to get in the way and cause you issues.
Talking about custom changes to Markdown leads me neatly into the next point. I will, probably, completely change the way blog posts are handled.
At the moment, blog posts are stored in the SQLite database, and blog post’s images are handled... well that’s another feature, like drafts, I didn’t realise I needed to handle until I started writing this blog post. I manually rsync’d the images for this post onto the server.
An article I read a little while ago which really caught my imagination, and that I haven’t seen mentioned much online, was this blog post announcing iA Writer 4.
In it they mentioned a quote from John Gruber about Markdown’s image syntax (which I keep forgetting).
My best idea for good Markdown img syntax would be to just paste in a URL ending in .jpg/.png/.gif etc.
I’ve already mentioned I think the image syntax should be expanded to include .mp4, .mp3, etc... However, iA Labs took the idea a step further. This allows tables, source code and even other bits of text to be separated into external csv, source and text files.
They even have an example spec for file transclusion, as the concept is named.
My revised handling of blog posts would look much more like iA Writer’s handling of its library, or even how I handle the portfolio, than it looks at the moment.
Root
+-- blog/
| +-- posts/
| | *-- "year"/
| | | Each year with its own directory.
| | | *-- "post_title"/
| | | | Each post has its own directory
| | | +-- info.json
| | | | This file defines the title, description, author, tags, and publish/modification date
| | | +-- post.md
| | | | This would be the custom CommonMark for the post itself.
| | | `-- resources/
| | | | This directory would be contain the images, text files and other files referenced in the post.md file.
I considered including the metadata at the top of the post.md file, like some websites do, but I prefer a slightly more structured layout.
Ideally, the python application would monitor the posts directory for changes and delete the cached HTML for the relevant blog post when needed. Then, after a short delay it’d re-render the post’s cached HTML file.
I would still use the SQLite database. However, instead of being the primary location for posts to be stored it would mirror the tags, metadata and the full text of blog posts. Rather than loading in the markdown directly, I’d parse the markdown and extract just the text (in much the same way I currently generate the post’s word count) loading that into the database, to make use of the SQLite full text search.
Other items I have notes to add in the future include:
- Image uploading from my post editor
- A better admin page
- A web based portfolio project creation page/editor
Summary
I’m never completely satisfied with anything I make, there’s always another feature I could add, a better way to do something, a more efficient way to achieve what I already have.
However, I am proud of this website.
I have done other websites before, but they all used existing templates, a ready made CMS or were just a single static HTML page. This was my first real server side project, and one of my first attempts at doing the design for a larger project myself.